
Toon for Oracle: A Token-Efficient Data Format for LLMs
TL;DR: Toon is a data representation format that is optimized for usage for LLMs. With UC AI’s PL/SQL package, you can convert any JSON data to the Toon format.
AI needs good context
#Shortly after LLMs exploded, people noticed that for good-performing assistants, a crucial factor is the right context. So if you want to build an AI assistant or agent on your data, you won’t get around one of these techniques to feed the LLM with the necessary information to answer the question:
- Hardcoded context in system/user prompt:
- Run an SQL query and concatenate the results into the prompt.
- Run Retrieval Augmented Generation (RAG) and then feed the best matches to the LLM with the question.
- Tools that let the AI access more information ad hoc (only when needed):
- Dedicated functions (with parameters that run a query)
- Natural language to SQL
- RAG (again)
Tokens: being on a budget
#One core metric around LLMs is tokens. They define how much data an LLM can process, how much you have to pay for it, how fast the responses get, and how well the AI performs.
Models have a max tokens window limiting how much text they can process both in input and output. Because processing more of that takes more time and thus requires more energy, tokens used is the metric of how AI providers price their model use. And most crucially for this post, additional irrelevant tokens reduce response quality and increase hallucination risk.
That’s why we use RAG to split huge documents/books into chunks and try to find only the relevant parts for answering the question instead of giving the LLM the whole text. Kind of makes sense; good communication is efficient in only giving the necessary information (not too much, not too little).
You can use tools (like this from OpenAI) to visualize how text gets tokenized. A token is not a strict mathematical unit; it can include a single character, whole words of various lengths, or just part of a long word.

When the format requires many tokens
#A good prompt is probably already token optimized in only telling the LLM what it needs to know in the most efficient way. But when we feed the AI big amounts of data for the purpose of analysis, the picture is different. The most obvious choice would be to use something like JSON or XML, as they are well established and natively supported by Oracle. But let’s actually compare its token usage.
I have a query fetching the top 5 products and customers of my database.
SQL Query
SELECT JSON_OBJECT(
'top_products' VALUE (
SELECT JSON_ARRAYAGG(
JSON_OBJECT('name' VALUE product_name, 'total_sales' VALUE total_sales)
)
FROM (
SELECT p.product_name, SUM(dp.quote_price) AS total_sales
FROM EBA_SALES_DEAL_PRODUCTS dp
JOIN EBA_SALES_PRODUCTS p ON dp.product_id = p.id
GROUP BY p.product_name
ORDER BY total_sales DESC
FETCH FIRST 5 ROWS ONLY
)
),
'top_customers' VALUE (
SELECT JSON_ARRAYAGG(
JSON_OBJECT('name' VALUE customer_name, 'total_sales' VALUE total_sales)
)
FROM (
SELECT c.customer_name, SUM(d.deal_amount) AS total_sales
FROM EBA_SALES_DEALS d
JOIN EBA_SALES_CUSTOMERS c ON d.customer_id = c.id
GROUP BY c.customer_name
ORDER BY total_sales DESC
FETCH FIRST 5 ROWS ONLY
)
)
) AS analytics;
The result as JSON uses up a total of 150 tokens, whereas an XML representation uses 258. Note that I minified the documents, removing newlines and whitespace, as studies strongly suggest that modern LLMs don’t perform better on formatted JSON/XML [1][2].
JSON and XML previews
JSON (formatted for readability):
{
"top_products": [
{
"name": "Liquid Designer",
"total_sales": 90000
},
{
"name": "Symmetric 1000",
"total_sales": 82200
},
{
"name": "Osprey Enterprise Edition",
"total_sales": 65010
},
{
"name": "Symmetric 2100",
"total_sales": 47300
},
{
"name": "Peregrine Enterprise Edition",
"total_sales": 35000
}
],
"top_customers": [
{
"name": "Asymmetrical Antibiotics Inc",
"total_sales": 246285
},
{
"name": "Madison Materials",
"total_sales": 198474
},
{
"name": "Turbo Charged Migration Systems",
"total_sales": 38500
},
{
"name": "Acme Department of Transportation",
"total_sales": 25500
},
{
"name": "Acme Department of Taxation",
"total_sales": 14580
}
]
}
XML (formatted for readability):
<x>
<top_products>
<name>Liquid Designer</name>
<total_sales>90000</total_sales>
</top_products>
<top_products>
<name>Symmetric 1000</name>
<total_sales>82200</total_sales>
</top_products>
<top_products>
<name>Osprey Enterprise Edition</name>
<total_sales>65010</total_sales>
</top_products>
<top_products>
<name>Symmetric 2100</name>
<total_sales>47300</total_sales>
</top_products>
<top_products>
<name>Peregrine Enterprise Edition</name>
<total_sales>35000</total_sales>
</top_products>
<top_customers>
<name>Asymmetrical Antibiotics Inc</name>
<total_sales>246285</total_sales>
</top_customers>
<top_customers>
<name>Madison Materials</name>
<total_sales>198474</total_sales>
</top_customers>
<top_customers>
<name>Turbo Charged Migration Systems</name>
<total_sales>38500</total_sales>
</top_customers>
<top_customers>
<name>Acme Department of Transportation</name>
<total_sales>25500</total_sales>
</top_customers>
<top_customers>
<name>Acme Department of Taxation</name>
<total_sales>14580</total_sales>
</top_customers>
<x>
You can see that XML wastes plenty of tokens for its closing tags and the <> symbols. The JSON is way more compact, but you will still find many tokens unrelated to the content but related to the JSON syntax, like {}[]".
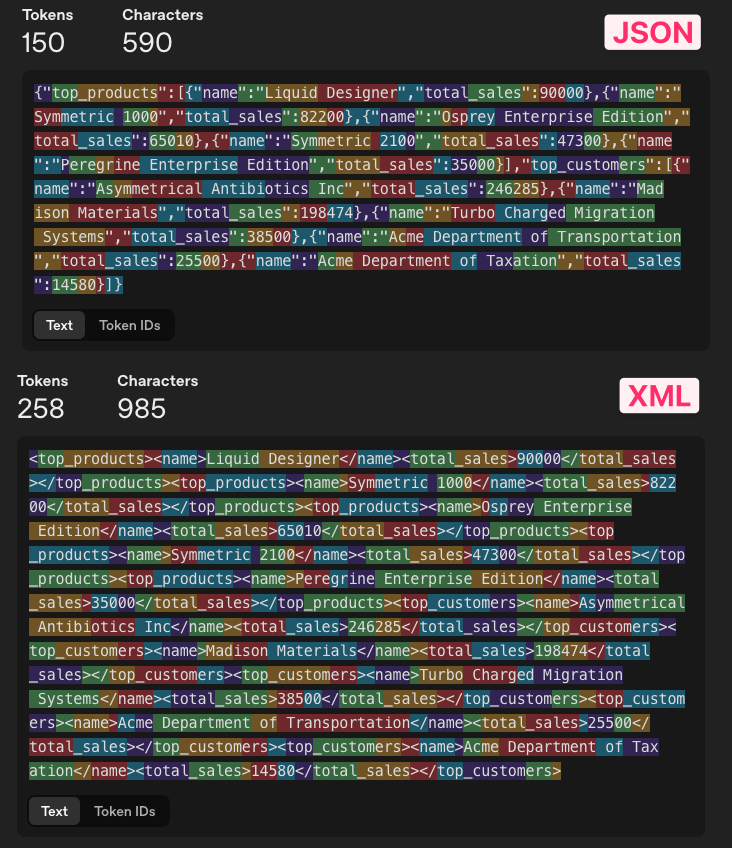
Toon: Less syntax please
#Token-Oriented Object Notation (in short, Toon), created by Johann Schopplich, tries to optimize the token usage further by using a mix of CSV and YAML syntax. It gets converted from a source JSON, so it supports any structures that JSON represents (unlike CSV, for example).
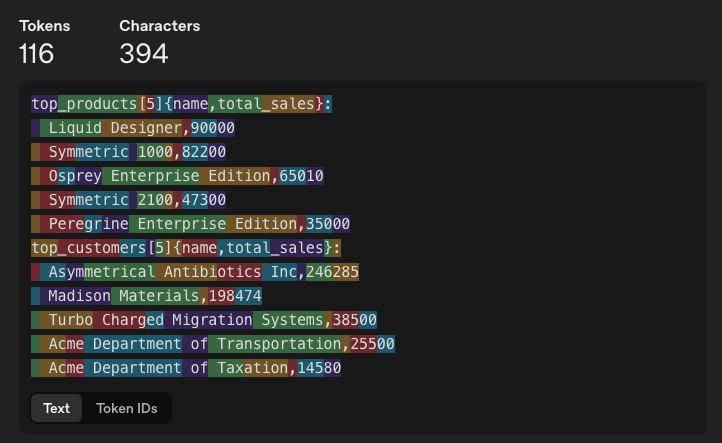
So this is how the same data looks in Toon:
top_products[5]{name,total_sales}:
Liquid Designer,90000
Symmetric 1000,82200
Osprey Enterprise Edition,65010
Symmetric 2100,47300
Peregrine Enterprise Edition,35000
top_customers[5]{name,total_sales}:
Asymmetrical Antibiotics Inc,246285
Madison Materials,198474
Turbo Charged Migration Systems,38500
Acme Department of Transportation,25500
Acme Department of Taxation,14580Toon uses strict indentations and newlines. For arrays, it also gives the count of rows, as LLMs are terrible at counting themselves. There are column headers in curly braces, and then it just displays the rows like CSV.
When we look at the tokenization, we see that it uses 116 tokens (~23% savings to JSON, ~55% savings to XML). For the data rows, most tokens are devoted to actual content.
For the small example, 34 fewer tokens does not mean the world, but if you feed huge amounts of data to LLMs frequently, an efficiency improvement of around 30% is actually not bad. Again, tokens are costs, speed, and accuracy, so that’s also a great metric to optimize for.
But be careful! Toon really excells if you have repeated structures, especially arrays of objects with the same keys. For just a single object with deep nesting, Toon could actually use more tokens than a minified JSON. So make sure to evaluate your specific use case.
How to Use Toon in Oracle
#The question is, how easily can you get the efficiency gains? I think the best place for this would be the database, where you should be able to query the data in Toon already. This is now possible with UC AI (my PL/SQL SDK for building AI workflows/agents in the Oracle Database):
SELECT uc_ai_toon.to_toon(JSON_OBJECT(
'top_products' VALUE (
SELECT JSON_ARRAYAGG(
JSON_OBJECT('name' VALUE product_name, 'total_sales' VALUE total_sales)
)
FROM (
SELECT p.product_name, SUM(dp.quote_price) AS total_sales
FROM EBA_SALES_DEAL_PRODUCTS dp
JOIN EBA_SALES_PRODUCTS p ON dp.product_id = p.id
GROUP BY p.product_name
ORDER BY total_sales DESC
FETCH FIRST 5 ROWS ONLY
)
),
'top_customers' VALUE (
SELECT JSON_ARRAYAGG(
JSON_OBJECT('name' VALUE customer_name, 'total_sales' VALUE total_sales)
)
FROM (
SELECT c.customer_name, SUM(d.deal_amount) AS total_sales
FROM EBA_SALES_DEALS d
JOIN EBA_SALES_CUSTOMERS c ON d.customer_id = c.id
GROUP BY c.customer_name
ORDER BY total_sales DESC
FETCH FIRST 5 ROWS ONLY
)
)
)) AS analytics;As Toon is designed to take a JSON input, you have to first query your data as JSON. Afterward you can pass it to the uc_ai_toon.to_toon function, which will return a CLOB. You can pass either Oracle’s JSON_OBJECT_T, JSON_ARRAY_T, or CLOB types.
If you want to convert JSON to Toon from PL/SQL, that is possible aswell:
declare
l_json clob;
l_toon clob;
begin
l_json := '{
"employees": [
{"name": "Alice", "age": 30, "department": "HR"},
{"name": "Bob", "age": 25, "department": "Engineering"},
{"name": "Charlie", "age": 28, "department": "Marketing"}
]
}';
l_toon := uc_ai_toon.to_toon(l_json);
sys.dbms_output.put_line(l_toon);
/*
employees[3]{name,age,department}:
Alice,30,HR
Bob,25,Engineering
Charlie,28,Marketing */
end;If you want to try it out yourself, you can just go to the packages folder on GitHub and download uc_ai_toon.pks and .pkb. I haven’t created a new release yet, so the package is not yet included in the download from the release page.
Some more examples of Toon
#Here are some more examples of how Toon represents different JSON structures:
Nested Object (minified JSON less tokens than Toon)
== JSON (formatted 159 tokens, minified 100 tokens) ==
{
"glossary": {
"title": "example glossary",
"GlossDiv": {
"title": "S",
"GlossList": {
"GlossEntry": {
"ID": "SGML",
"SortAs": "SGML",
"GlossTerm": "Standard Generalized Markup Language",
"Acronym": "SGML",
"Abbrev": "ISO 8879:1986",
"GlossDef": {
"para": "A meta-markup language, used to create markup languages such as DocBook.",
"GlossSeeAlso": [
"GML",
"XML"
]
},
"GlossSee": "markup"
}
}
}
}
}
== Toon (112 tokens) ==
glossary:
title: example glossary
GlossDiv:
title: S
GlossList:
GlossEntry:
ID: SGML
SortAs: SGML
GlossTerm: Standard Generalized Markup Language
Acronym: SGML
Abbrev: "ISO 8879:1986"
GlossDef:
para: "A meta-markup language, used to create markup languages such as DocBook."
GlossSeeAlso[2]: GML,XML
GlossSee: markup
Irregular Array
== JSON ==
[{"a":1},{"a":1,"b":2},{"c":3}]
== Toon ==
[3]:
- a: 1
- a: 1
b: 2
- c: 3
Object with different data types
== JSON ==
{"str": "text", "num": 42, "bool": true, "nil": null, "arr": [1, "two"]}
== Toon ==
str: text
num: 42
bool: true
nil: null
arr[2]: 1,two
Is Toon taking over the world?
#It might evoke the old CSV vs. JSON debates. But Toon has a very specific use case in mind, where it undoubtedly shines: feeding data to LLMs in a token-efficient way.
Where other formats are optimized for easy machine parsing or human readability, Toon focuses on being token efficient. So I don’t see it replacing any of the existing formats for general use. If you talk to an LLM, use Toon; if not, stick to JSON or XML.
It is also pretty early days for Toon. The first commit to the spec was done on the 2nd of November, 2025. There are probably things that will change over time. I actually have a niche case in one of my tests where I deliberately deviate from the spec in adding an indentation level, as it makes more sense in my opinion.
I will try to keep the implementation in UC AI up to date with the spec and add new features as they come. If you have ideas or find issues, please open them on the UC AI GitHub repo.
Additionally, if you have a very irregular JSON structure, it could be that it does not translate well to Toon. In that case, sticking to JSON is probably the better choice.